Nota do Editor: Este post faz parte da Série decodificada por IAque desmistifica a inteligência artificial, tornando a tecnologia mais acessível e introduz novos hardware, software, ferramentas e acelerações para usuários de PCs GeForce RTX e estações de trabalho NVIDIA RTX.
Os grandes modelos de linguagem (LLMs) estão remodelando a produtividade. Eles podem redigir documentos, resumir páginas da web e, tendo sido treinados em grandes quantidades de dados, responder com precisão a perguntas sobre quase todos os tópicos.
Os LLMs estão no centro de muitos casos de uso emergentes em IA generativa, incluindo assistentes digitais, avatares de conversação e agentes de atendimento ao cliente.
Muitos dos LLMs mais recentes podem ser executados localmente em PCs ou estações de trabalho. Isso é útil por vários motivos: os usuários podem manter conversas e conteúdos privados no dispositivo, usar inteligência artificial sem Internet ou simplesmente aproveitar as vantagens das poderosas GPUs NVIDIA GeForce RTX em seu sistema. Outros modelos, devido ao seu tamanho e complexidade, não cabem na memória de vídeo GPU local (VRAM) e requerem hardware em grandes data centers.
No entanto, é possível acelerar parte de um prompt em um modelo de classe de data center localmente em PCs baseados em RTX usando uma técnica chamada descarregamento de GPU. Isso permite que os usuários se beneficiem da aceleração da GPU sem serem limitados pelas restrições de memória da GPU.
Tamanho e qualidade acima do desempenho
Existe uma compensação entre o tamanho do modelo e a qualidade das respostas e do desempenho. Em geral, modelos maiores fornecem respostas de maior qualidade, mas são executados mais lentamente. Com modelos menores, o desempenho aumenta enquanto a qualidade diminui.
Este compromisso nem sempre é simples. Há casos em que o desempenho pode ser mais importante que a qualidade. Alguns usuários podem priorizar a precisão para casos de uso como geração de conteúdo, já que ela pode ser executada em segundo plano. Enquanto isso, um assistente de conversação deve ser rápido e, ao mesmo tempo, fornecer respostas precisas.
Os LLMs mais precisos, projetados para serem executados no data center, têm dezenas de gigabytes de tamanho e podem não caber na memória de uma GPU. Tradicionalmente, isso impediria que o aplicativo aproveitasse a aceleração da GPU.
No entanto, o descarregamento da GPU usa parte do LLM na GPU e parte na CPU. Isso permite que os usuários aproveitem ao máximo a aceleração da GPU, independentemente do tamanho do modelo.
Otimize a aceleração de IA com descarregamento de GPU e LM Studio
LM Studio é um aplicativo que permite aos usuários baixar e hospedar LLM em seus desktops ou laptops, com uma interface fácil de usar que permite ampla personalização de como esses modelos funcionam. O LM Studio é baseado em llama.cpp, portanto é totalmente otimizado para uso com GPUs GeForce RTX e NVIDIA RTX.
O LM Studio e o descarregamento de GPU aproveitam a aceleração de GPU para melhorar o desempenho de um LLM hospedado localmente, mesmo que o modelo não possa ser totalmente carregado na VRAM.
Com o descarregamento da GPU, o LM Studio divide o modelo em partes menores, ou “subgráficos”, que representam camadas da arquitetura do modelo. Os subgráficos não são fixados permanentemente na GPU, mas carregados e baixados conforme necessário. Com o controle deslizante de descarregamento de GPU do LM Studio, os usuários podem decidir quantas dessas camadas são processadas pela GPU.
Por exemplo, imagine usar esta técnica de descarregamento de GPU com um modelo grande como o Gemma 2 27B. “27B” refere-se ao número de parâmetros no modelo, fornecendo uma estimativa da quantidade de memória necessária para executar o modelo.
De acordo com a quantização de 4 bits, técnica para reduzir o tamanho de um LLM sem reduzir significativamente a precisão, cada parâmetro ocupa meio byte de memória. Isso significa que o modelo deve exigir cerca de 13,5 bilhões de bytes, ou 13,5 GB, além de algum overhead, que geralmente varia de 1 a 5 GB.
Acelerar este modelo inteiramente na GPU requer 19 GB de VRAM, disponíveis na GPU de desktop GeForce RTX 4090. Com descarregamento de GPU, o modelo pode rodar em um sistema com uma GPU de baixo custo e ainda se beneficiar da aceleração.
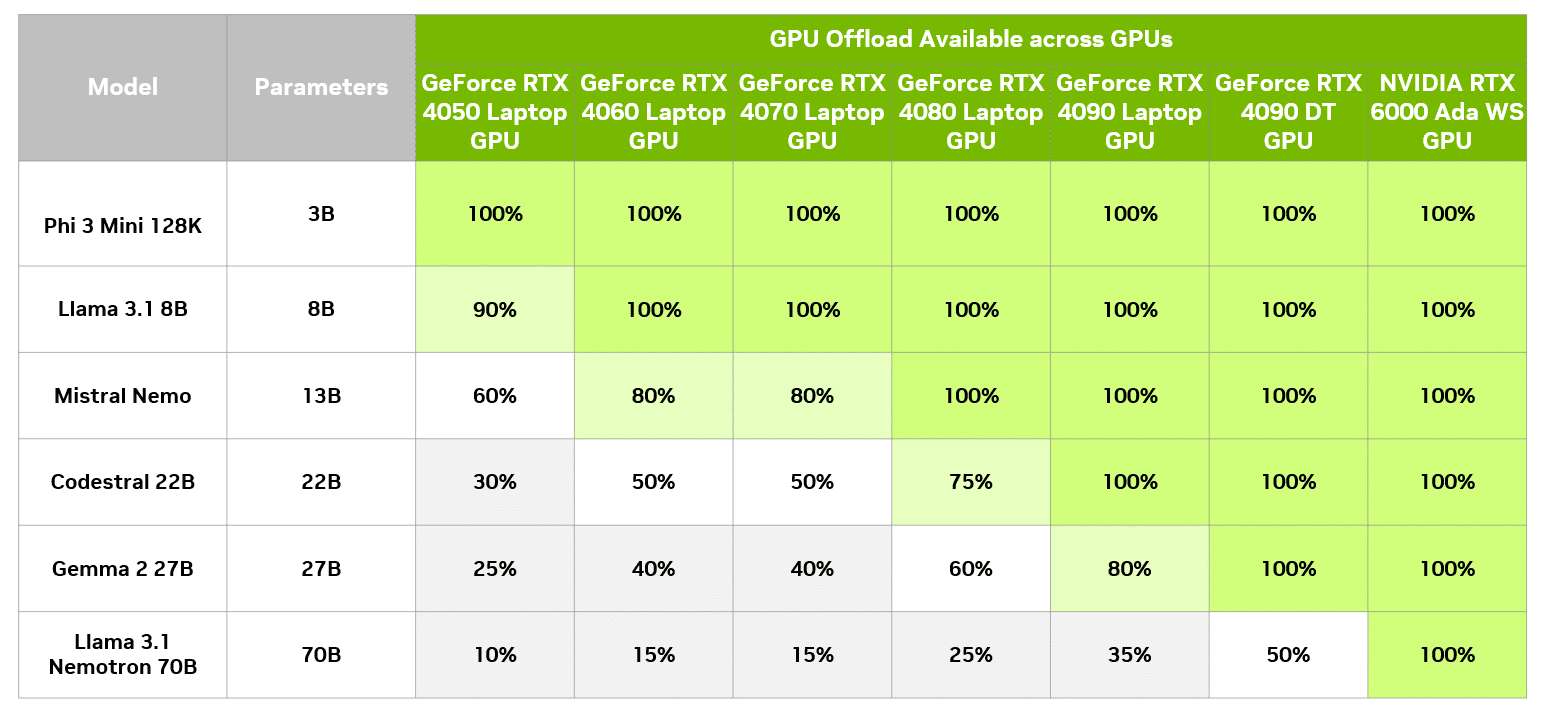
No LM Studio, você pode avaliar o impacto no desempenho de diferentes níveis de descarregamento da GPU, em comparação apenas com a CPU. A tabela a seguir mostra os resultados da execução da mesma consulta em diferentes níveis de descarregamento em uma GPU de desktop GeForce RTX 4090.

Neste modelo específico, mesmo os usuários com uma GPU de 8 GB podem desfrutar de um aumento notável de velocidade em relação ao uso apenas da CPU. Claro, uma GPU de 8 GB sempre pode rodar um modelo menor que cabe inteiramente na memória da GPU e obter aceleração total da GPU.
Alcance o equilíbrio ideal
O recurso de descarregamento de GPU do LM Studio é uma ferramenta poderosa para desbloquear todo o potencial de LLMs projetados para o data center, como o Gemma 2 27B, localmente em PCs RTX AI. Ele torna modelos maiores e mais complexos acessíveis a toda a linha de PCs baseados em GPU GeForce RTX e NVIDIA RTX.
Baixe o LM Studio para testar o descarregamento de GPU em modelos maiores ou experimente uma variedade de LLMs acelerados por RTX executados localmente em PCs e estações de trabalho RTX AI.
A IA generativa está transformando jogos, videoconferências e experiências interativas de todos os tipos. Confira o que há de melhor e mais recente assinando Boletim informativo de IA decodificado.