
Grandes modelos de linguagem e os aplicativos que eles potencializam oferecem às organizações oportunidades sem precedentes para obter insights mais profundos de seus reservatórios de dados e criar classes inteiramente novas de aplicativos.
Mas as oportunidades muitas vezes vêm acompanhadas de desafios.
Seja no local ou na nuvem, os aplicativos que devem ser executados em tempo real impõem demandas significativas à infraestrutura do data center para fornecer simultaneamente alto rendimento e baixa latência com um investimento em uma única plataforma.
Para impulsionar melhorias contínuas de desempenho e melhorar o retorno sobre investimentos em infraestrutura, a NVIDIA otimiza regularmente modelos de comunidade de ponta, incluindo o Llama da Meta, o Gem do Google, o Phi da Microsoft e nosso recém-lançado NVLM-D-72B semanas atrás. atrás.
Melhorias contínuas
As melhorias de desempenho permitem que nossos clientes e parceiros sirvam modelos mais complexos e reduzam a infraestrutura necessária para hospedá-los. A NVIDIA otimiza o desempenho em todos os níveis da pilha de tecnologia, incluindo TensorRT-LLM, uma biblioteca desenvolvida especificamente para oferecer desempenho de ponta nos LLMs mais recentes. Com melhorias no modelo Llama 70B de código aberto, que oferece altíssima precisão, já melhoramos o desempenho da latência mínima em 3,5x em menos de um ano.
Melhoramos constantemente o desempenho da nossa plataforma e publicamos regularmente atualizações de desempenho. Aprimoramentos nas bibliotecas de software da NVIDIA são lançados semanalmente, permitindo que os clientes obtenham mais das mesmas GPUs. Por exemplo, em questão de meses, melhoramos o desempenho do nosso Llama 70B de baixa latência em 3,5x.
Na rodada mais recente do MLPerf Inference 4.1, apresentamos nossa primeira apresentação com a plataforma Blackwell. Oferece desempenho 4 vezes maior que a geração anterior.
Esta apresentação também foi a primeira apresentação do MLPerf a usar a precisão FP4. Formatos de precisão mais estreitos, como FP4, reduzem o consumo de memória e o tráfego, além de aumentar o rendimento computacional. O processo aproveita o Transformer Engine de segunda geração da Blackwell e, com as técnicas avançadas de quantização que fazem parte do TensorRT Model Optimizer, o produto da Blackwell atendeu às rigorosas metas de precisão do benchmark MLPerf.
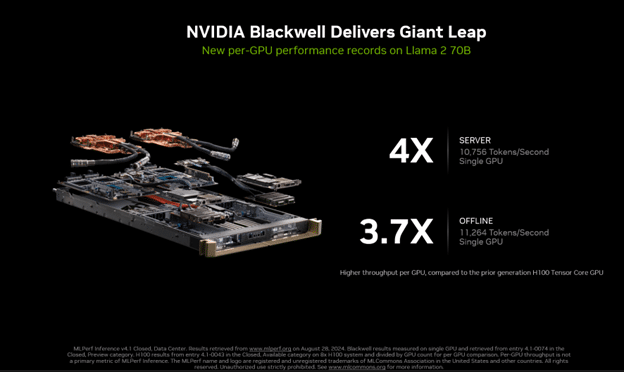
As melhorias na Blackwell não impediram a aceleração contínua de Hopper. No ano passado, o desempenho do Hopper aumentou 3,4x no MLPerf no H100 graças aos avanços regulares do software. Isso significa que o desempenho máximo da NVIDIA hoje no Blackwell é 10x mais rápido do que era há apenas um ano no Hopper.
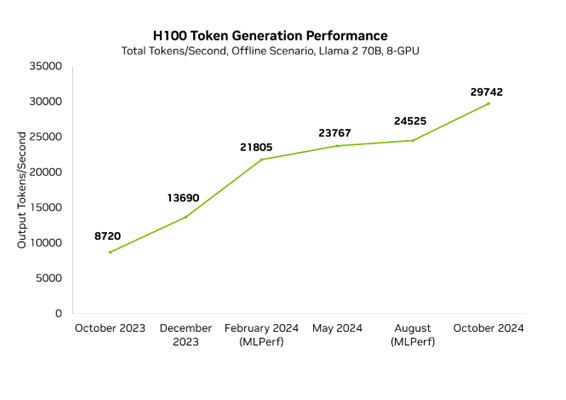
Nosso trabalho contínuo é incorporado ao TensorRT-LLM, uma biblioteca desenvolvida especificamente para acelerar o LLM que contém otimizações de última geração para executar inferências com eficiência em GPUs NVIDIA. O TensorRT-LLM é baseado na biblioteca TensorRT Deep Learning Inference e aproveita muitas das otimizações de aprendizado profundo do TensorRT com aprimoramentos adicionais específicos do LLM.
Melhorando a lhama aos trancos e barrancos
Mais recentemente, continuamos a otimizar variações dos modelos Llama do Meta, incluindo as versões 3.1 e 3.2, bem como o modelo de tamanho 70B e o modelo maior, 405B. Essas otimizações incluem receitas de quantização personalizadas, bem como o uso eficiente de técnicas de paralelização para dividir o modelo com mais eficiência em várias GPUs, aproveitando as tecnologias de interconexão NVIDIA NVLink e NVSwitch. LLMs de última geração, como o Llama 3.1 405B, são muito exigentes e exigem o desempenho combinado de várias GPUs de última geração para respostas rápidas.
As técnicas de paralelismo requerem uma plataforma de hardware com uma estrutura robusta de interconexão GPU-GPU para atingir o desempenho máximo e evitar gargalos de comunicação. Cada GPU NVIDIA H200 Tensor Core possui NVLink de quarta geração, fornecendo uma enorme largura de banda de GPU para GPU de 900 GB/s. Cada plataforma HGX H200 de oito GPUs também vem com quatro switches NVLink, permitindo que cada GPU H200 se comunique com qualquer outra GPU H200 a 900 GB/s, simultaneamente.
Muitas implantações de LLM usam paralelismo em vez de optar por manter a carga de trabalho em uma única GPU, o que pode apresentar gargalos de computação. Os LLMs procuram equilibrar baixa latência e alto rendimento, com a técnica de paralelização ideal dependendo dos requisitos da aplicação.
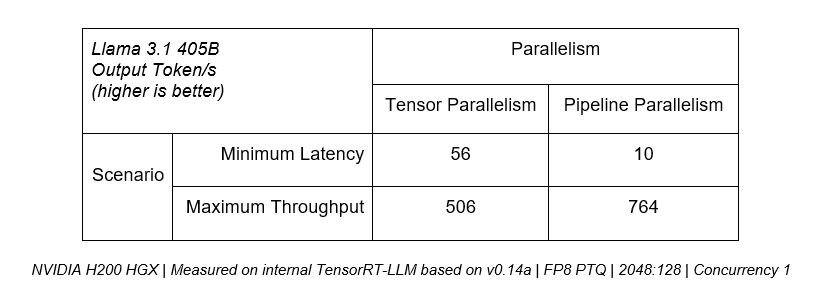
Por exemplo, se a prioridade for a latência mais baixa, o paralelismo do tensor é crítico, pois o desempenho computacional combinado de múltiplas GPUs pode ser usado para entregar tokens aos usuários mais rapidamente. No entanto, para casos de uso em que o rendimento máximo de todos os usuários é priorizado, o paralelismo de pipeline pode aumentar com eficiência o rendimento geral do servidor.
A tabela a seguir mostra que o paralelismo de tensor pode fornecer uma taxa de transferência 5x maior em cenários de latência mínima, enquanto o paralelismo de pipeline fornece desempenho 50% maior para casos de uso de taxa de transferência máxima.
Para implantações de produção que buscam maximizar o rendimento dentro de um determinado orçamento de latência, uma plataforma deve fornecer a capacidade de combinar efetivamente ambas as técnicas, como no TensorRT-LLM.
Leia o blog técnico do Llama 3.1 405B Throughput Enhancement para saber mais sobre essas técnicas.
O ciclo virtuoso
Ao longo do ciclo de vida de nossas arquiteturas, oferecemos melhorias significativas de desempenho por meio de ajuste e otimização contínuos de software. Estas melhorias traduzem-se em valor acrescentado para os clientes que treinam e implementam as nossas plataformas. Eles são capazes de criar modelos e aplicativos mais capazes e implementar modelos existentes usando menos infraestrutura, melhorando o ROI.
À medida que novos LLMs e outros modelos generativos de IA continuam a chegar ao mercado, a NVIDIA continuará a executá-los bem em suas plataformas e a torná-los mais fáceis de implantar com tecnologias como microsserviços NIM e NIM Agent Blueprints.
Saiba mais com estes recursos: